Last updated: April 09, 2024
Incremental data quality monitoring for partitioned data
This guide shows how to detect data quality issues in time-based or partitioned data, monitoring very big or append-only tables, detecting issues ahead of time.
Measuring quality of partitioned data
DQOps was designed from the bottom-up to support analyzing data quality of very big tables, reaching even terabyte and petabyte scale. Very big tables are rarely fully reloaded every day. Instead, the tables are appended, and old data is not modified.
Date partitioned data is analyzed by DQOps by adding a GROUP BY time_period_column clause to SQL queries executed on the monitored data source. Please look at the documentation of the daily_partition_nulls_percent check to see the examples of SQL queries that are rendered for different database engines.
Checking new data
Data quality platforms that are not able to apply time partitioning are limited to detect data quality issues at a whole table level.
Let's consider the following example of detecting that recent the rows received recently are incomplete (<10% of not null rows), while the average of not null rows was above 90% for several years.

By analyzing data grouped by time periods, DQOps can detect a recent drop in data quality instantly. Also, the data quality KPI that is calculated monthly, will be decreased by a drop of data quality in recently loaded rows.
Monitoring vs partitioned checks
DQOps takes a different approach for calculating data quality KPIs by monitoring and partitioned data quality checks.
-
Monitoring checks analyze the whole table
-
Daily monitoring checks are executed daily, capturing the data quality check result for each day. The data quality KPI for daily monitoring checks counts the number of days in the month when the data quality check passed, as shown in the data quality formulas above.
-
Monthly monitoring checks capture only one data quality result per month. The default CRON schedule for executing monthly checks runs them once a day, but only the most recent result for the current month is stored in the data quality data warehouse. Monthly monitoring checks are used, when the data quality KPI should measure the end-of-month data quality status, instead of measuring the number of days when the data quality rules were satisfied.
-
-
Partitioned checks analyze data by grouping by a date column for incremental data quality analysis
-
Daily partitioned checks group rows by configuring the partition_by_column column. Data quality KPIs calculated monthly are evaluated for each daily partition.
-
Monthly monitoring checks group rows also by the partition_by_column column, but an additional truncation of the date is applied. The date column is truncated to the beginning of the month. Data quality SQL queries executed by DQOps measure the quality of the whole month of data.
-
Physical partitioning
When query performance and the impact of the data quality platform on the monitored data source is important, the monitored tables that are analyzed with time partitioning should be physically partitioned by the date column that DQOps will use in grouping.
Queries generated by DQOps use the column's data type that was captured when the table's metadata was imported into DQOps. The imported data type is stored in the column type snapshot of the .dqotable.yaml file. Daily partitioned checks apply a date truncation function on the partition_by_date column, unless the known data type is DATE, when no truncation is used.
Logical date partitioning of financial data
The monitored tables do not need to be physically partitioned by a date column to benefit from date partitioned data quality checks. You can select any date, datetime or timestamp column as the selected partition_by_column name, to be used by partitioned checks.
DQOps was designed with focus for measuring the data quality of financial data, when the current and previous month are the focus for data quality analysis.
Configuring incremental data quality monitoring
Partitioned data quality checks are designed for running incrementally, to analyze only the most recent data. DQOps generates data quality SQL queries with an additional WHERE partition_by_column >= [first date] filter condition.
Configuring incremental time windows
The configuration of the default time windows for daily and monthly partitioned checks is configured in the Date and time columns tab on the table's metadata screen.
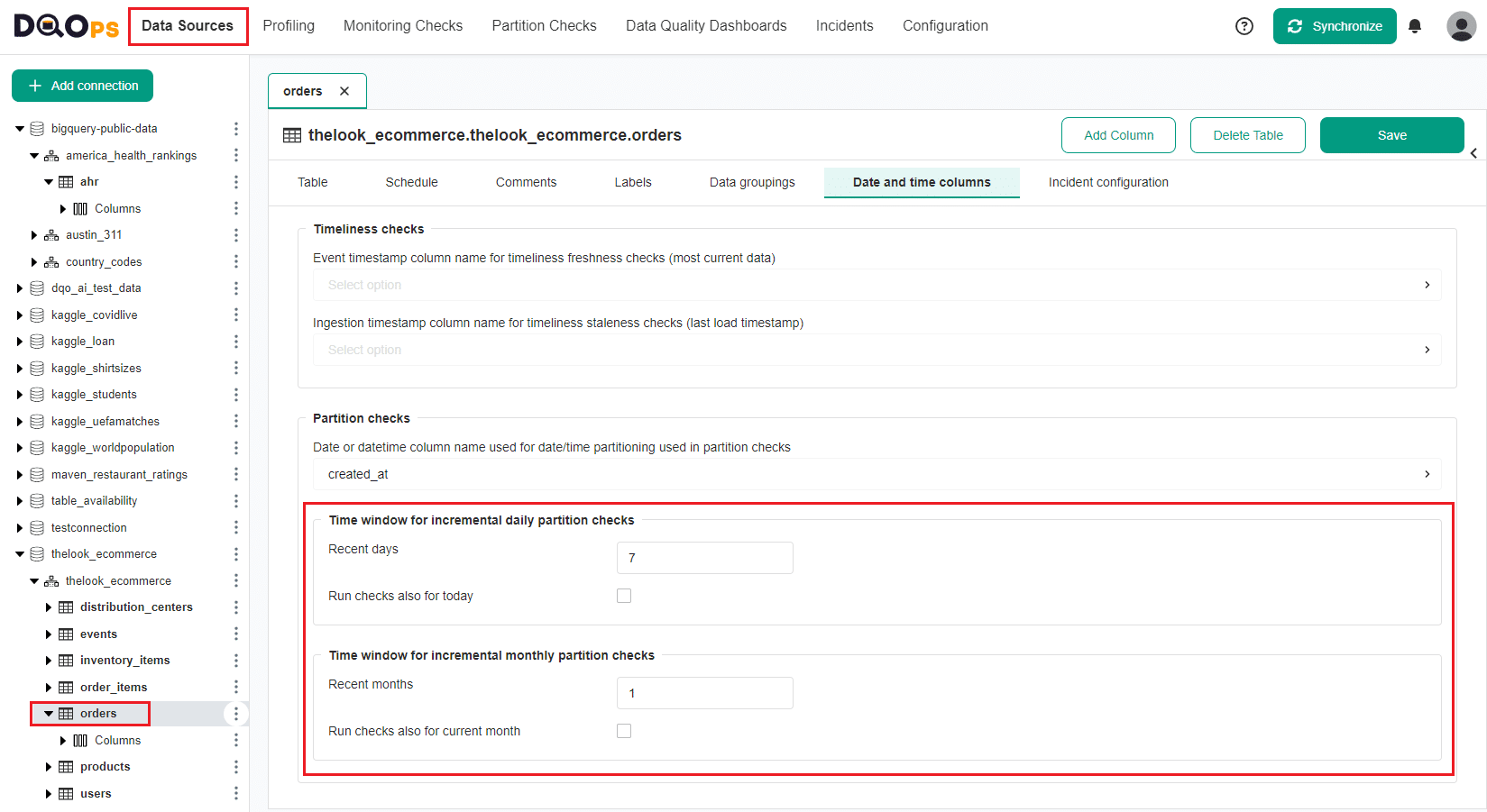
Running checks for different time windows
Partitioned checks can be executed for a different time window directly from the data quality check editor screen as shown below.

Also, all configured partitioned checks can be executed directly from the tree view on the left.
The metadata tree nodes that support running checks are:
- data source
- schema
- table
- column
- single check
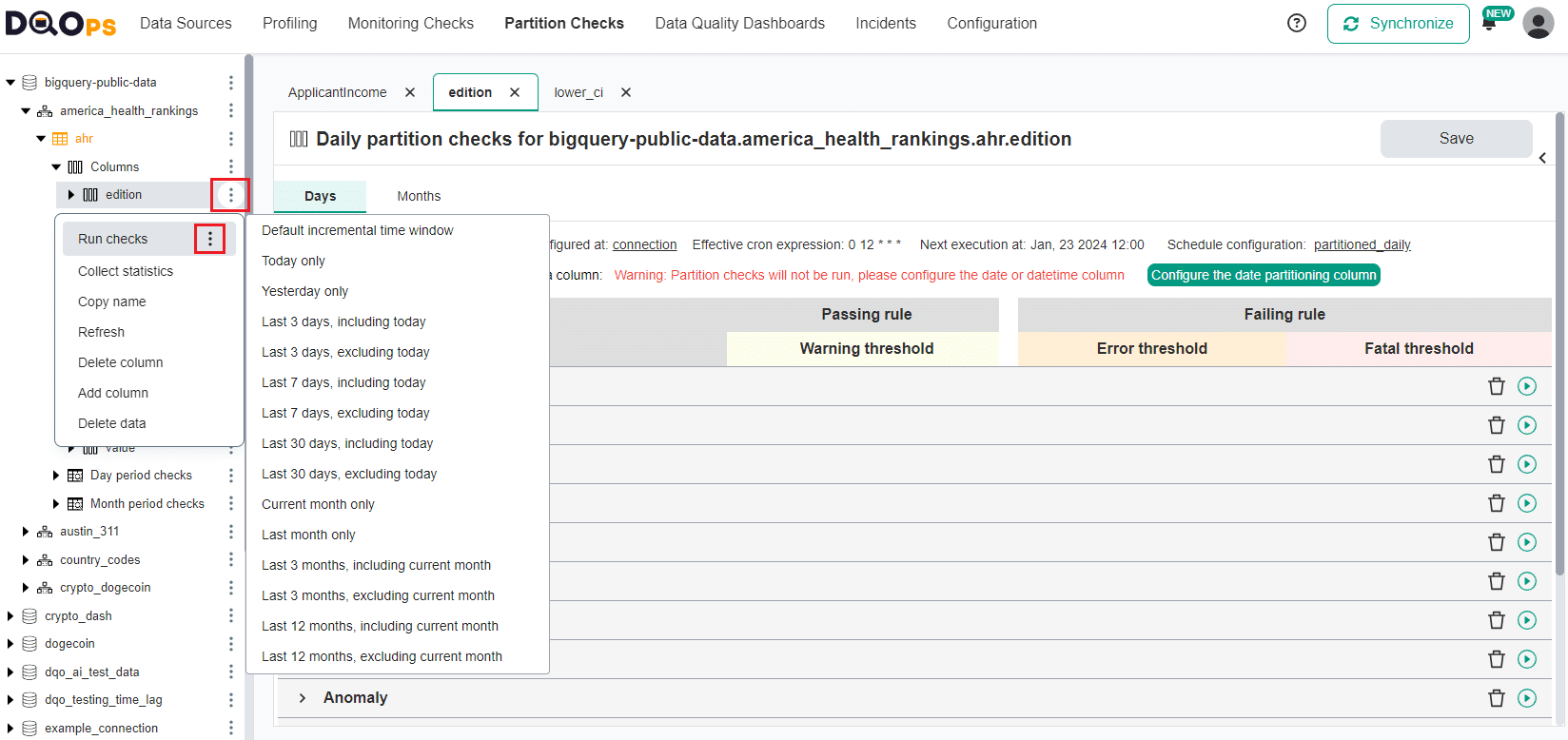
By running data quality checks incrementally, DQOps avoids additional pressure on the monitored data source. When the table is physically partitioned by the column used by partitioned checks and the time window filter is passed to the database, all modern databases will apply a partition elimination optimization to scan only the data in the selected time window. By default, that is the last 7 days for daily partitioned checks and last month for monthly partitioned checks.
Benefits of incremental data quality monitoring
Detect issues early
New data quality issues usually appear in new data, when the source system was updated, the data model has changed, or some change were made in the data pipeline code.
In that case, the old that that was already loaded, is not affected by the data quality issue. When the old records are not updated often or at all in the data source, corrupted records will be present only in the most recent data. The most recent data for one day is just 0.0273% of all records for one year (0.0273% is 1/365). When the table holds data for 5 years, one day is just 0.000547% of all rows. Noticing a drop of daily_nulls_percent score for the whole table by just 0.000547% will go unnoticed if the data quality checks analyze the whole table.
Partitioned checks in DQOps, such as daily_partition_nulls_percent, will detect the data quality issue on the first day when corrupted records reach the data platform.
Analyze large tables
Large tables at terabyte or petabyte scale require partitioning to be queried efficiently. By configuring the default incremental time windows for running partitioned checks, only the most recent data will be analyzed.
DQOps also automatically analyzes all SQL data quality queries and merges queries that are analyzing the same table (a common table in the FROM clause). For example, when 2 different data quality checks are configured for each of 50 columns on a single table, instead of running 100 SQL queries (2 checks * 50 columns), DQOps will merge all data quality SQL queries into one long query that will analyze the table in a single pass.
Analyze fact tables
Fact tables, especially those using slowly changing dimensions, are naturally designed for data quality with date partitioned data quality checks. When you are connecting DQOps to a fact table, always configure the partition_by_column column name on the Date and time columns table's tab.
The partition_by_column should be the name of the date dimension column.
Analyze append-only tables
All other tables that track financial transactions and cannot be modified are obvious candidates for incremental data quality monitoring because only the most recent data can change, and the old records are not modified.
Analyze financial data
The tables that are tracking financial transactions are usually append-only tables. The time periods of interest for financial data is aligned with tax reporting periods (i.e. monthly), or fiscal years. In both cases, using the monthly partitioned checks enables tracking the quality of all financial data for one month.
The financial data from the previous month is considered complete when all data quality checks for the previous month passed. That is why many of the data quality dashboards in DQOps have filters to select teh current month and the previous month. The data for the current month is still arriving and can be affected by data quality issues, but the data for the past month must pass the data quality KPIs for all required data quality dimensions.

What's next
- Learn how data quality KPIs data quality KPIs are measured
- Find out more about partitioned checks
- Learn how DQOps stores the results of partitioned checks