Last updated: April 09, 2024
Partitioned data quality checks
Read this guide to understand how data quality checks in DQOps are applied to analyzing partitioned data, or time-based data such as financial records.
What are partition checks?
The partition(ed) checks in DQOps are responsible for monitoring data quality for date partitioned data, or to detect data quality issues in append-only tables.
The partitioned data quality checks run SQL queries on monitored tables adding a GROUP BY TRUNCATE(<timestamp_column>) clause,
capturing results for every daily or monthly partition.
The data quality results generated by partitioned checks are stored
for every date or month of data.
Capturing data quality results for time periods is important for:
- storing an audit log of executed data quality checks for partitions
- analyzing financial data, when only the most recent data for the current or previous month is important, and older financial records are read-only (closed)
- measuring very big tables, even at terabyte and petabyte scale with incremental data quality monitoring
- measuring data quality KPIs at a partition level
- detecting data quality issues early when the issue affected only the most recently loaded data, but only <1% or 0.1% of rows is affected (one day out of 3 years of data)
Before activating a data quality partitioned check, you should test a profiling version of the data quality check. Every monitoring and partition data quality check has a profiling version, named as profiling_*.
Tables do not need to be physically partitioned by date to benefit from partitioned checks
DQOps does not require that tables are physically time-partitioned. You can use partitioned checks to analyze any table that has a timestamp column, such as: transaction timestamp, event timestamp, created at timestamp, impression timestamp.
Time scale
Partitioned checks are divided into two groups, having almost the same data quality checks.
- daily partitioned checks track the data quality status for each day
- monthly partitioned checks track the data quality status for each month, but are not supporting anomaly detection checks because one data quality result per month is not enough to use prediction
Summary
The following table summarizes the key concepts of partitioned data quality checks in DQOps, divided by daily partitioned and monthly partitioned checks.
| Check type | Time scale | Purpose | Time period truncation | Check name prefix |
|---|---|---|---|---|
| partitioned | daily | Daily partitioned checks store the data quality status for each day of data, analyzing daily partitions or any table in daily time periods. | One data quality monitoring result captured per daily partition. When a daily partitioned check is run again any time, the previous result for that daily time_period is replaced. |
daily_partition_* |
| partitioned | monthly | Daily partitioned checks store the data quality status for each month of data, analyzing monthly partitions or any table in monthly time periods. | One data quality monitoring result captured per monthly partition. When a monthly partitioned check is run again any time, the previous result for that monthly time_period is replaced. |
monthly_partition_* |
SQL queries for partitioned checks
The following example shows an SQL query generated by DQOps to run the daily_partition_nulls_percent check that groups rows by the date column, aggregating (truncating) the data quality measures by date, without the time.
The date column used for grouping by a time period in the example above is the "transaction_date".
The column name must be configured, which is described in the setting up date partitioning column later.
Partitioned checks in DQOps user interface
Daily partitioning
Daily partitioned checks truncate the column used for partitioning to the beginning of the day.
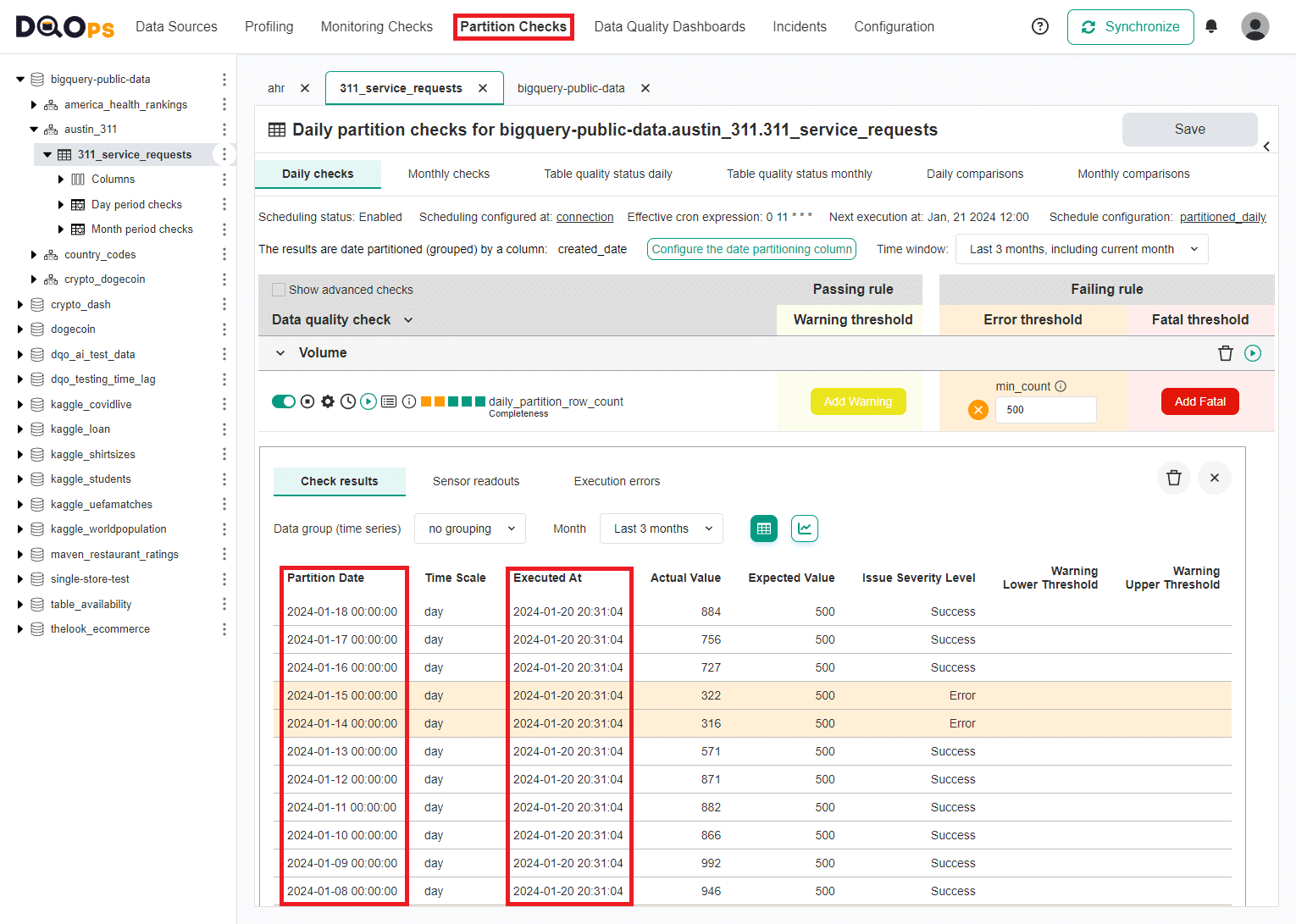
The following example uses a sample table with a history of 911 service requests, the data is partitioned by the created_date column.
A daily_partition_row_count check was run for the last 11 daily partitions, using an error severity rule that raises a data quality issue when the number of rows in a daily partition is below 500 rows.
The issue was detected on January 14th, 2024 and January 15th, 2024. The results are highlighted with an orange color for error severity issues.
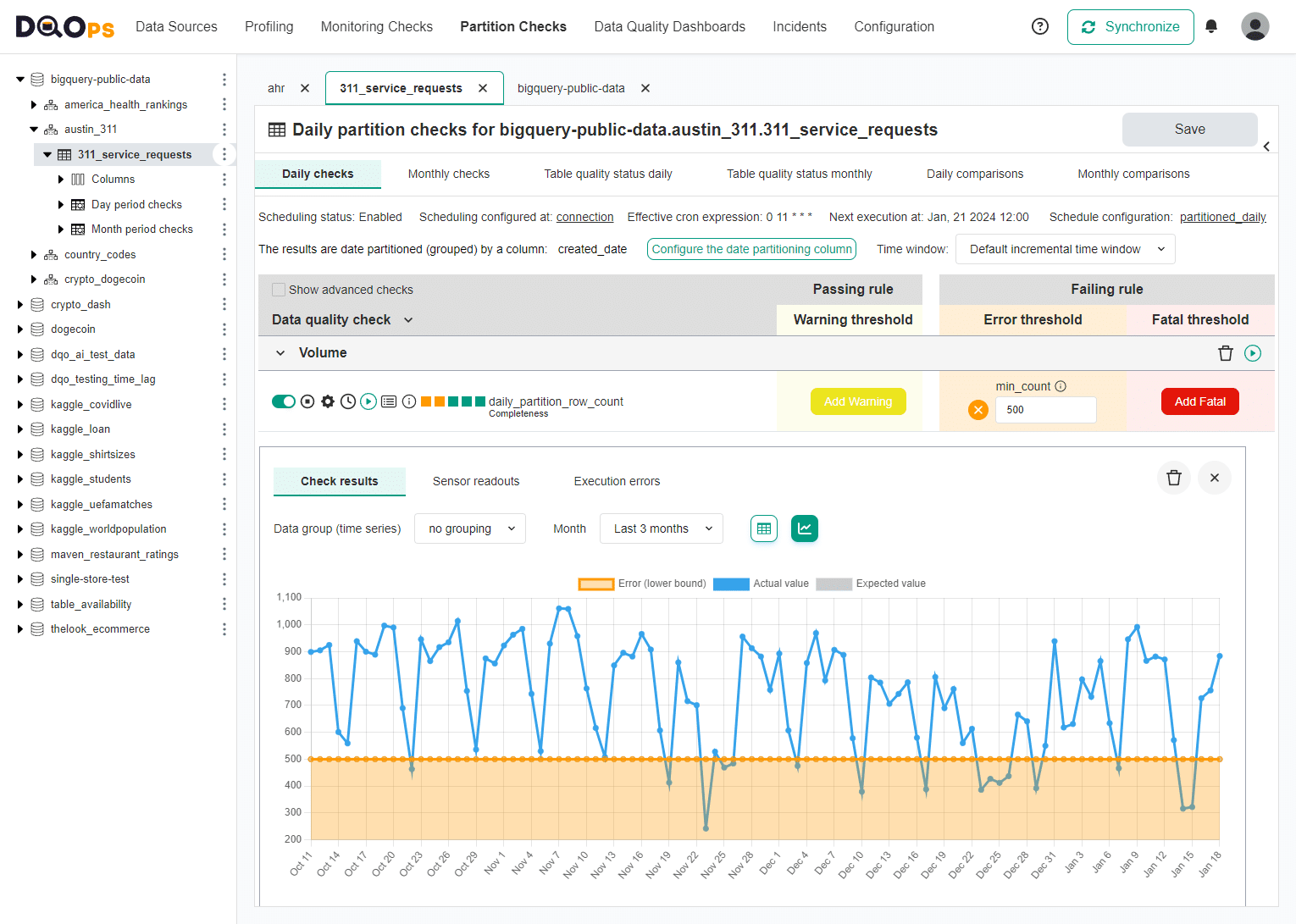
A longer history of partition volume (row counts) is shown when switching the view to a chart mode. The orange area limited from the top at 500 rows is the error severity threshold. Any data quality results for daily partition below 500 rows are data quality issues when the volume of the partition for that day was below a minimum required size.
Monthly partitioned checks
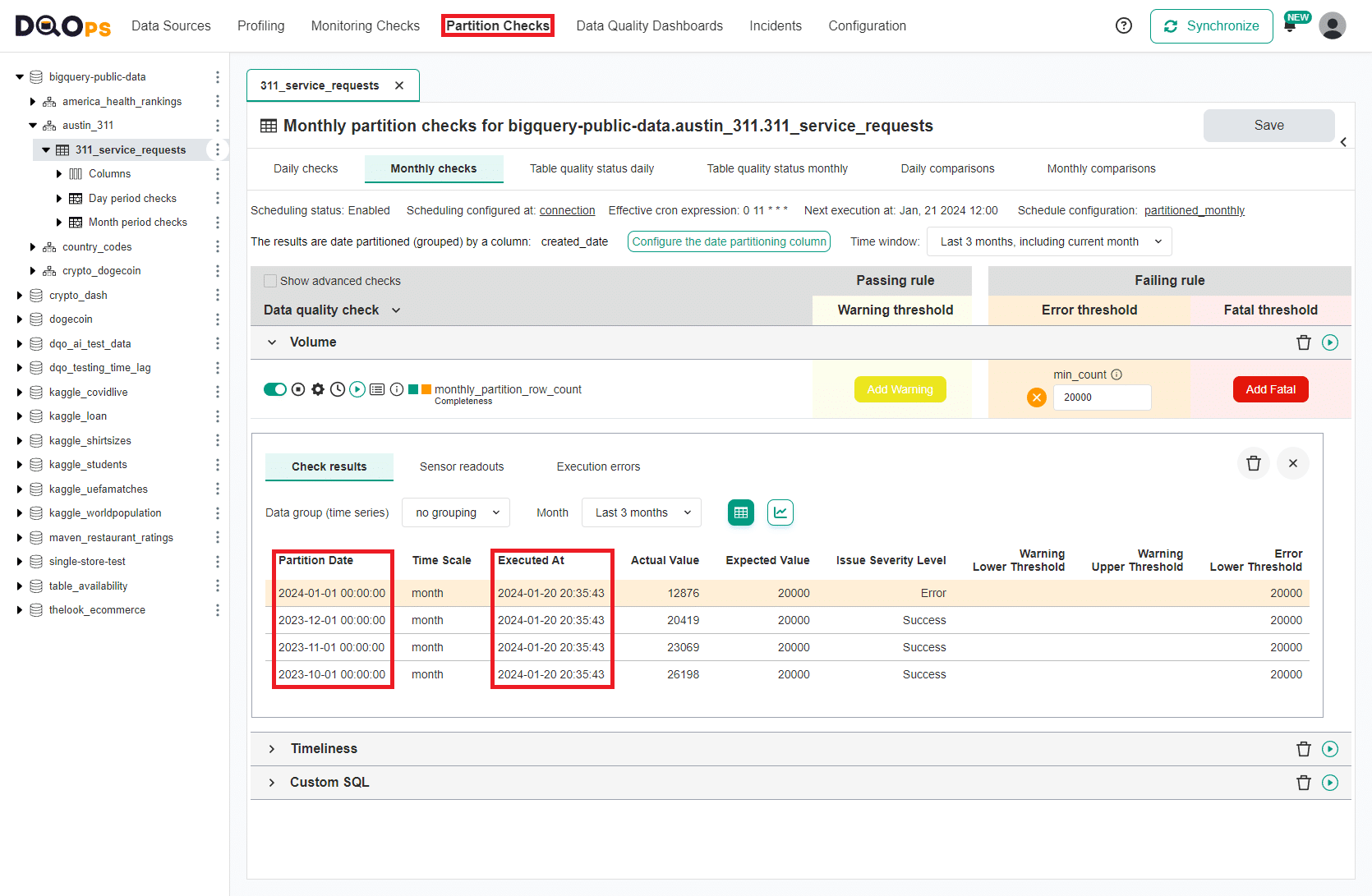
Monthly partitioned checks truncate the column used for partitioning to the beginning of the month.
A monthly_partition_row_count check was run for the last 4 monthly partitions, using an error severity rule that raises a data quality issue when the number of rows in a month is below 20000 rows.
The row counts for October, November and December 2023 met the volume requirement. The monthly data quality check was run at 2024-01-20 20:35:43 (shown as the Executed At timestamp). Not all data for the current month (January 2024) were received yet, and the table had only 12876 rows. An error severity issue was raised, because the minimum accepted monthly row count is 20000 rows.
Using monthly partitioned checks to analyze the current month
The example above shows a challenge with analyzing partitioned data for the current month (monthly partitioned data), and for today (by daily partitioned checks). Some data quality checks may fail during the month, because not all data for that time period was received yet.
The configuration parameter to enable analyzing also today's data or the data for the current month is shown in the next section setting up date paritioning column.
Setting up date partitioning column
To run partition checks you need to configure a date or datetime columns which will be used as the time partitioning key for the table.
DQOps will use this column in the GROUP BY clause, truncating the date to the beginning of the day (daily partitioned checks)
or the 1st day of the month (monthly partitioned checks).
Configure partitioning column in the user interface
When you navigate to the Partition checks section and choose a table or column that has not been configured with a date partitioning column, a red warning message will appear above the Check editor saying Partition checks will not be run, please configure the date or datetime column. Furthermore, this column will be highlighted in orange in the tree view on the left side of the screen.

To enable the time partition check, set a column that contains the date, datetime, or timestamp.
-
Go to the Data Sources section.
-
Select the table of interest from the tree view.
-
Select the Data and time columns tab and in the Partition checks section, select a column from the drop-down list in the "Date or datetime column name used for date/time partitioning used in partition checks" input field.
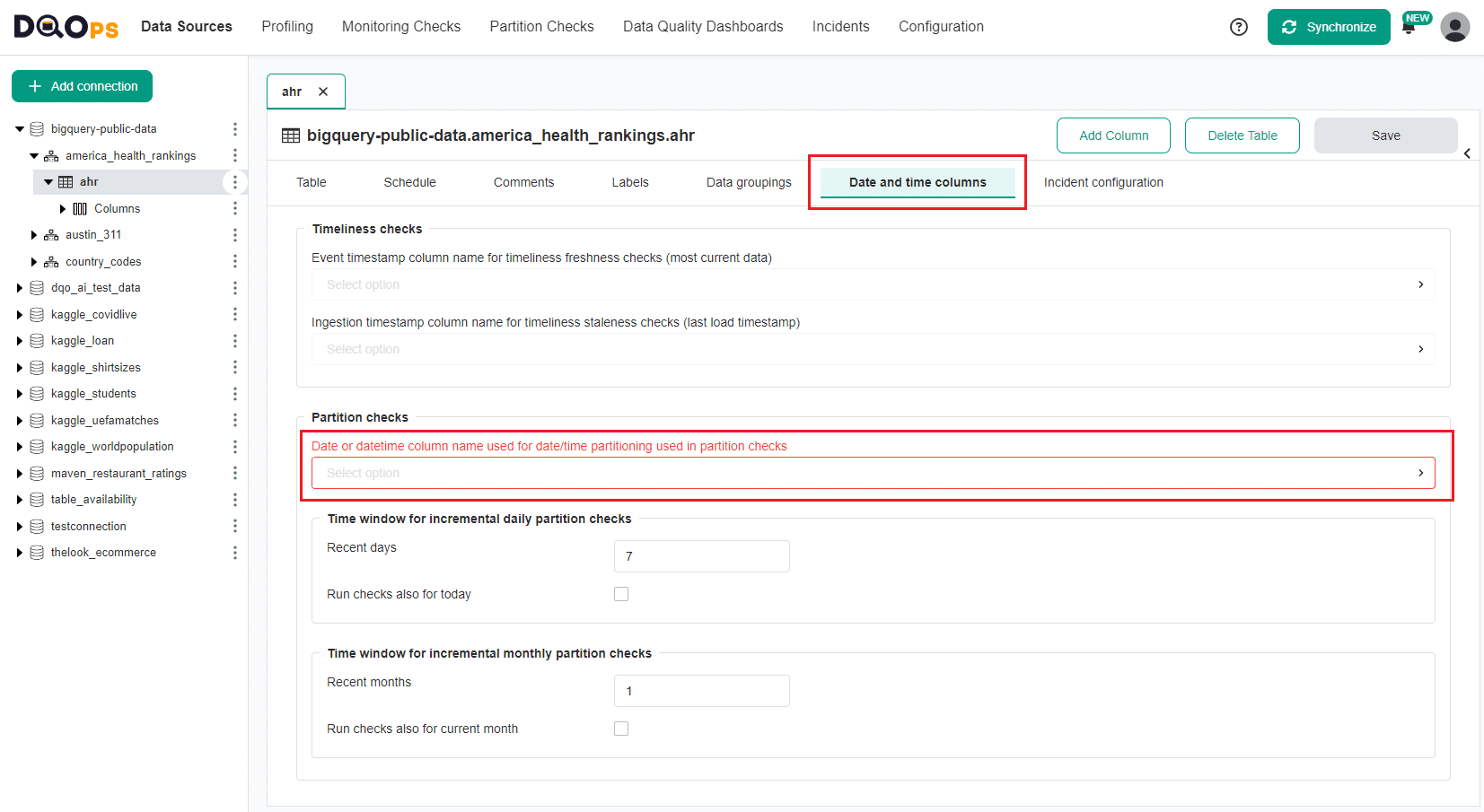
You can also get to this screen by clicking the Configure the date partitioning column button located on the screen with a list of partition checks.
-
Click the Save button in the upper right corner.
-
Click on the Partition Checks section at the top of the screen, to return to the partitioned checks section.
Configure partitioning column in the YAML file
The date or datetime column for partition checks can be also configured by adding the appropriate parameters to the YAML configuration file.
Below is an example of the YAML file showing a sample configuration with set datetime column event_timestamp for partition
checks partition_by_column.
apiVersion: dqo/v1
kind: table
spec:
target:
schema_name: target_schema
table_name: target_table
timestamp_columns:
event_timestamp_column:
ingestion_timestamp_column:
partition_by_column: event_timestamp
Difference between partitioned and monitoring checks
The difference between partitioned check and monitoring is compared in the table below.
| Check type | Range of rows for data quality issues | Data quality result storage |
|---|---|---|
| monitoring | Monitoring checks analyze the whole table. An update to the oldest record in the table can trigger a data quality issue. | Stores one result per day or month when the data quality check was run, adding a new result in the next day or in the next month. |
| partitioned | Partitioned checks use a GROUP BY time_period clause in SQL queries, analyzing rows for each day or month separately. A change such as null values in an old partition caused by reloading a partition with corrupted data generates a data quality issue with a time period in the past. |
Stores one result for each daily or monthly partition, replacing data quality results when a partitioned check is run again with different rules, or the data in the partition has changed. |
Partitioned checks pros and cons
When to use partitioned checks
Use the partitioned checks to:
-
Track and checkpoint the data quality for daily partitioned data, capturing separate data quality metrics and results for each partition
-
Analyze append-only tables, such as fact tables in data warehouses
-
Analyze financial data that should not change, when the month or year is closed
-
Analyze very big tables incrementally, scanning only the most recent partitions, and avoiding additional pressure on the data source from a data quality platform
-
Detect data quality issues early using incremental data quality monitoring
-
Analyze the quality of data in the landing zone, especially when the landing tables use automatic time partitioning and partition expiration managed by the database engine.
Limitations of partitioned checks
The results of partitioned data quality checks are used to evaluate the data quality KPI and compliance with data contracts at a partition level.
-
Do not use partitioned checks for the first time before experimenting with a profiling variant of that check. The configuration of accepted profiling checks can be easily converted to partitioned checks. If a misconfigured partitioned check is run and fails, raising a data quality issues, the issues will decrease the data quality KPI score. You will have to use the delete data quality results screens to remove these data quality results.
-
Monthly partitioned checks do not support anomaly detection data quality checks, because when only one data quality result for each data quality check is stored per month, there is not enough historical data to use prediction.
-
Do not analyze decommissioned tables that were not updated for more than 3 months, even if they are date or time partitioned physically. The data quality check editor in DQOps is designed to show the results for the last 3 months, plus the current month. The data quality results for older partitions will not be shown.
Partition check configuration in DQOps YAML files
The configuration of active data quality partition checks is stored in the .dqotable.yaml files. Please review the samples in the configuring table metadata article to learn more.
-
configuring table-level partition checks shows how to configure partitioned checks at a table level
-
configuring column-level partition checks shows how to configure partitioned checks at a column level
What's next
- Learn how to assess the initial data quality status using profiling checks.
- Learn how to checkpoint the data quality of whole tables using monitoring checks.
- Read the configuring table-level partition checks and configuring column-level partition checks to learn the details of configuring partition checks in YAML files.
- Learn how to use partition checks in to detect data quality issues incrementally using DQOps.
- Learn how DQOps calculates the data quality KPI score